
교차분석은 관심 있는 표본으로부터 Categorical(명목형) 데이터에 대하여 pivot table이나 cross table (contingency table)을 만들어 행과 열을 교차하여 교차빈도집계표를 구한 후에 χ²검정을 이용하여 동질성, 독립성을 검정하는 것으로 끝장을 보는 분석입니다. 그러니까 이것도 다른 통계분석처럼 특정한 데이터 처리절차를 거친 후에 χ²검정으로 주장의 정당성을 부여하는 절차라고 보면 틀림없습니다.
그러니까, 조금 더 풀어서 이야기한다면, 바로 전에 살펴본 피봇테이블(pivot table) 또는 교차집계표 crosstab을 이용하거나 해서 최종 교차빈도집계표(cross tabulation, contingency table)를 만들 수만 있으면 분석을 위한 데이터 처리 절차가 완료된 것이고, 곧바로 χ²검정에 돌입할 수 있겠습니다. 이 순간을 위하여 "독립성(연관성), 동질성 검정의 차이와 그들의 정체 - χ² 카이스퀘어 검정"편에서 카이제곱검정을 열심히 해 두었으니까, 마음이 든든합니다.

어쨌거나 χ²검정을 손으로 이미 풀어봤으니까, 이번에는 손으로 풀지 않고 scipy를 이용하여 분석→검정→연관도확인 까지 쫘르륵해 보도록 하겠습니다요.
자, 그러면 어떤 데이터 모음이 있습니다. 어떤 데이터냐면
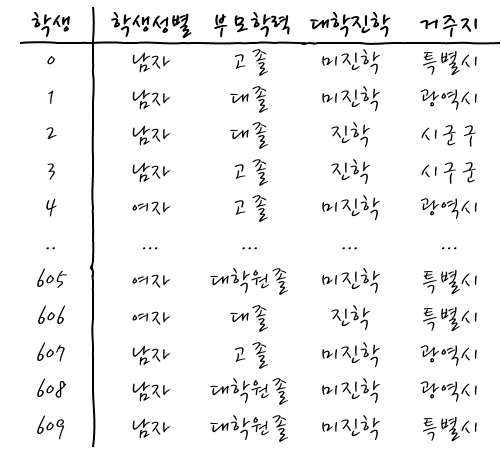
뭐 요런 데이터입니다. 학생이 각 row에 있고, 컬럼은 학생성별, 부모학력, 대학진학, 거주지의 데이터입니다. - pandas의 df_data에 적재되어 있는 데이터입니다 - 전체 610명의 데이터니까 꽤 크군요. 이런 데이터가 있으니까 뭔가 당연한 본능이겠지만 각 컬럼 간의 관계를 보고 싶겠습니다. - 그것이 교차분석이니까요. - 과연 관계가 있을까...?요
그전에 이래 봬도 분석 후에 χ²검정을 하니까, χ²검정에 대한 가설을 설정한다면,
H0 : 두 변수는 독립이다.
H1 : 두 변수는 독립이 아니다. (연관이 있다)
로 설정할 수 있겠습니다.
변수를 특정하지 않고, 두 변수라고 일반적인 문구를 쓴 것은 이제부터 두 변수들을 여러 개로 해서 볼 것이라서 그렇게 설정했으니까, 이해해 주세요.
그럼 처음에 궁금한 것은 거주지에 따라 대학 진학이 차이가 나는지 궁금해 미치겠는데요 - 궁금해 미쳐줘요 - , 교차집계표를 이용해서 한번 확인해 보시죠. (crosstab을 이용하던지, pivot_table을 이용하던지 해서 만들 수 있다는 점. 잊지 않기 위해서 계속 되풀이합니다.)
df_cross_table = pd.crosstab(df_data['거주지'], df_data['대학진학'])
df_cross_table = pd.pivot_table(df_data, index='거주지', columns='대학진학', aggfunc="size")
>
대학진학 미진학 진학
거주지
광역시 90 122
시구군 42 50
시군구 16 30
특별시 110 150
간단하게 교차집계표를 만들었습니다. 후후.
그러면, 곧바로 짜잔! χ²검정을 할 수가 있는데, 이미 한번 해 보았으니까, 쓱싹쓱싹. 가 보겠습니다.
from scipy.stats import chi2_contingency
chi2_contingency(rows, correction=False)
이렇게 할 수 있겠습니다만, 엇, rows에는 교차표의 각 row가 각각 list로 들어가야 하니까, 조금 손을 보면 좋겠군요. 걍 각 row에 대한 list를 만들어서 넣으면 됩니다. 머리에 그려지지 않을 수 있으니까, 이 것은 [[90, 122],[42, 50], [16, 30], [110, 150]] 의 형태가 되어야 합니다. 그러면 그렇게 만든 후에 슥슥 검정을 해 보시죠.
rows = [row.to_list() for i, row in df_cross_table.iterrows()]
chi2_contingency(rows, correction=False)
>
(1.490709512981629,
0.6844162240071692,
3,
array([[ 89.66557377, 122.33442623],
[ 38.91147541, 53.08852459],
[ 19.4557377 , 26.5442623 ],
[109.96721311, 150.03278689]]))
홋, p value가 0.68이니, 거주지에 따른 대학진학결과는? 서로 독립이라고 볼 수 있겠습니다. 서로 영향을 미치지 않는 거죠. 약간 지역에 따른 차이가 있지 않을까 생각했는데, 그렇지는 않군요. 밋밋하네요. 참고로, 검정 결과를 읽기 위해서 부연하자면, 결과의 첫 번째는 카이제곱 통계량, 두 번째는 p value, 세 번째는 자유도, 마지막은 서로 독립일 때의 Expected 빈도의 row list입니다.
이 정도 되면 또 궁금한 게 또 생기겠죠? 당연히. 학생 성별 간에 대학 진학결과가 차이가 있을까? 하는 궁금증인데요, 그러면 또 쓱싹쓱싹 해 볼까요?
df_cross_table = pd.crosstab(df_data['성별'], df_data['대학진학'])
>
대학진학 미진학 진학
학생성별
남자 142 204
여자 116 148
rows = [row.to_list() for i, row in df_cross_table.iterrows()]
chi2_contingency(rows, correction=False)
>
(0.5156124572911421,
0.4727193075636217,
1,
array([[146.34098361, 199.65901639],
[111.65901639, 152.34098361]]))
오, 성별과 대학 진학과의 관계도 독립이군요. 성별이 대학 진학결과에 영향을 미치지 않는다고 봐야 하겠습니다. 그냥 데이터만 보면 남학생과 여학생의 절대수가 달라서 차이가 나지 않을까 하고 언뜻 생각했는데, 그렇지는 않군요.
그럼, 이제는 진짜 마지막으로 부모의 학력이 대학 진학에 영향을 끼치는지 한번 보겠습니다. 이거 뭔가 영향을 끼친다면 정말 흥미진진한 결과가 되겠는걸요. 쓱싹쓱싹.
df_cross_table = pd.crosstab(df_data['부모학력'], df_data['대학진학'])
>
대학진학 미진학 진학
부모학력
고졸 112 126
대졸 70 140
대학원졸 76 86
rows = [row.to_list() for i, row in df_cross_table.iterrows()]
chi2_contingency(rows, correction=False)
>
(10.539167067134844,
0.005145753160303171,
2,
array([[100.66229508, 137.33770492],
[ 88.81967213, 121.18032787],
[ 68.51803279, 93.48196721]]))
엇! 부모의 학력과 진학은 서로 독립이 아니군요?? 서로 영향을 끼칩니다. 오, 새로운 발견입니다. 조금 흥분되는군요. 서로 연관이 있다면 얼마나 연관이 있는지도 보면 좋겠는데 말이죠.
갑자기 이런 말을 꺼내서 미안합니다만, 이런 명목형 변수 - 명목형 변수 (Categorical - Categorical)를 분석하는 경우에는 크래머V (Cramer V)라는 것을 이용해서 얼마나 서로 연관되어 있는지 볼 수 있습니다. 먼저 연관도가 무엇인지 살펴보는 준비운동 없이 갑자기 들이대는 것은 초큼 미안하긴 합니다만, 그래도 지금 어떤 것인지 들여다보는 것이 가장 자연스러운 이야기라고 생각합니다.
$Cramer V = \sqrt{\cfrac{\chi_{stat}^2\div n}{min(r-1, c-1)}}$
이 식이 Cramer V - 연관 계수, 크래머 브이라고 읽습니다. -를 정의하는 식인데요, 이 연관 계수에 대해 조금 이해하고 넘어가자면, χ²의 결괏값은 고정된 같은 확률에 대해서 전체 표본의 개수가 크면 큰 값이 나와야 하는 경향이 있고, 그러니까, 그 효과를 없애기 위해서 n으로 나누고 난 후에, 이 나눈 값의 최댓값이 min(r-1, c-1)이 되거든요? (이 값은 Cramer의 phi, φ값이라고 하는데, Cramer가 열심히 연구해서 최대값이 min(r-1, c-1)이라고 알아냈다고 하니, 받아들이는 편이 속 편하겠습니다.) 그래서 min(r-1, c-1)로 나누어서 0~1 사이의 값으로 정규화를 한 것입니다. 그러니까, n으로 나누기 전의 χ²통계량이 n에 비해 훨씬 극단적이어야 Significant할 수 있고, Significant한 경우에 더 극단적일 수록 연관도가 크게 나온다는 뭐 그런 스토리입니다.
"어쨌든 χ² 값과 관련되어 있으니까 서로 독립일 때 기대했던 값과 차이가 많이 날 수록 더 연관되어 있다고 생각하는 것입니다." (중요)
자, 그러면 결과를 계산해 본다면,
χ² = 10.539167067134844
n = 610
c = 2 (열, column의 개수)
r = 3 (행, row의 개수)
min(r-1, c-1) = 1
이 값들을 직접 넣어서 손으로 계산해도 되고,
import numpy as np
x2 = chi2_contingency(rows, correction=False)[0]
n = np.sum(rows)
minDimension = min(np.array(rows).shape)-1
V = np.sqrt((x2/n) / minDimension)
print(V)
>
0.13144323132393237
이런 식으로 계산해도 됩니다. 간단하지요? 흠. 결과는 0.131 정도니까 서로 영향을 끼치긴 하지만, 그렇게 큰 영향은 아니군요. 어쨌든 0.131 정도의 서로의 연관성을 가지고 있습니다. 통계적으로 유의하고, 약한 연관관계를 가지고 있다 정도로 해석하면 되겠습니다. 보통 0.6 이상이 되면 강한 연관관계가 있다고 볼 수 있겠습니다.
더 간단한 이야기를 하자면,
from scipy.stats.contingency import association
association(rows, method="cramer")
이렇게 간단하게 라이브러리를 쓸 수도 있습니다.
교차분석이라는 것은 태평하게도 이런 식으로 흘러가는 이야기인 것입니다.

굉장히 중요한 이야기를 하면 도움이 될 것 같은데, 연관성과 상관성에 대한 이야기입니다. 도대체 이 둘의 차이는 무엇인가? 하면 연관성은 상호 영향을 미치는 것을 모두 연관성이라고 하고, 상관성은 선형관계를 가지고 있는가를 따지는 것입니다. 그러니까 연관성은 비선형 관계를 말할 수도 있고, 이번에 따져본 것과 같이 서로 독립이 아닌 경우에 어느 정도 서로 영향을 미치는지를 를 말할 수도 있고, 그리고 당연히 상관성을 가질 때에도 연관성을 가진다고 말할 수 있겠습니다. 그러니까 연관성이 상관성 보다는 어느 면에서는 조금 더 큰 개념이라고 볼 수 있겠네요.

그렇긴 한데, 중간에 Cramer V 계수 이야기를 하면서 갑자기 표본의 크기가 클수록 χ²통계량이 크다는 이야기를 갑자기 꺼냈는데, 처음 듣는 이야기 아닌가요? 어찌 되었건 이게 무슨 이야기인가 볼 필요가 있겠는데, 가장 쉬운 방법을 택한다면, χ²통계표를 보면 단박에 이해가 갑니다.
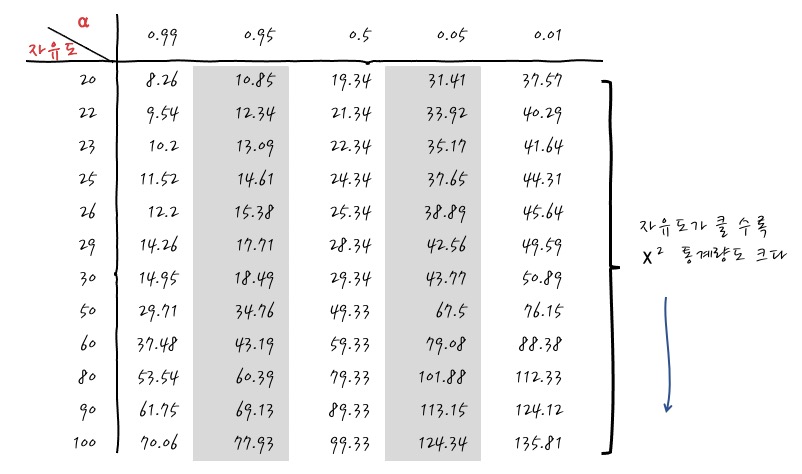
잘 보면 아래 방향으로 자유도 - 자유도가 표본의 크기와 관계가 있다는 사실을 잊은 건 아니겠죠. - 가 커지면 같은 유의확률에 대해서 χ²통계량도 같이 커짐을 볼 수 있겠습니다. 이 말은 같은 유의확률 하에서 Null Hypothesis가 기각되기 위해서는 더 많이 Extraordinary해야 (더 극단적이어야) Significant하다는 의미입니다. 뭐, 어찌 보면 당연한 이야기겠군요. Cramer V의 경우에는 n이 커질수록 더 많이 극단적일 수록 연관도가 높다고 본다는 의미입니다. 표본수가 커질 수록 더 엄격하게 봐야 한다는 것이겠죠. 이건 그냥 상식 정도로 알고 있으면 어디 가서 잘난 척은 할 수 있지 않을까 하고 생각하고 있습니다.
 친절한 데이터 사이언스 강좌 글 전체 목차 (정주행 링크) -
친절한 데이터 사이언스 강좌 글 전체 목차 (정주행 링크) - 
댓글